



Here at SpatialDev we continue to push the boundaries of geospatial technologies with the goal of providing the best possible solutions for our clients. Be it state of the art mobile data collection applications or GeoSPARQL-enabled linked data triple stores, we are constantly exploring new and innovative answers to the tasks and problems that we are presented.
One of the recent areas of research that we’ve been exploring on the data science team is topic extraction from unstructured natural language. The significant increase in user-generated content over the past few years, spurred by advanced use in social media platforms and mobile-based contribution application, has given rise to an unprecedented amount of noisy, grammatically complex, spelling-error ridden, but contextually rich textual content online. The difficulty lies in extracting meaning from these data. Given the shear amount of content, it is often better to look at a corpora of documents as a whole rather than a set of individual contributions.
One of the methods that we’ve been using to approach this problem of extracting meaning from large corpora of unstructured text is latent Dirichlet allocation (LDA). LDA is a state-of-the-art topic modeling technique which takes a generative, unsupervised probabilistic topic modeling approach to infer latent topics in a large textual corpus. A topic in this case is a multinomial distribution over terms, where the distribution describes the probabilities that a topic will generate a specific word. LDA models each document as a mixture of these topics based on a Dirichlet distribution. The end result of this process is that we can quantitatively describe each document (e.g., a blog post) as a weighted distribution of topics. For example, this blog post would likely prove to be low in the topic of “Mexican food and restaurants” but high in a topic related to “technology and communication,” purely based on the co-occurrence of words in and across this and other blog posts.
An example of the work that we’ve been doing in this domain can be seen in a short paper recently published at the Location-Based Social Networking workshop (in conjunction with the ACM SIGSPATIAL conference) in Seattle, WA this week. In short, the purpose of the work is to show the spatial, textual and thematic differences between Twitter and the new social media application on the block, Yik Yak. Both Twitter and Yik Yak allow users to contribute short snippets of geotagged social content, but Yik Yak has the added bonus of being completely anonymous. This small, but significant difference then begs the question, does the content contributed by users of these two platforms differ, and if so how? To explore this question from a thematic (topic) perspective we employed LDA along with multidimensional scaling (MDS) to map the differences in multidimensional topic space to two dimensional space so that it can be better visualized, and hopefully conceptualized. The results of this LDA/MDS approach can be seen in the figure below (taken from the published article)
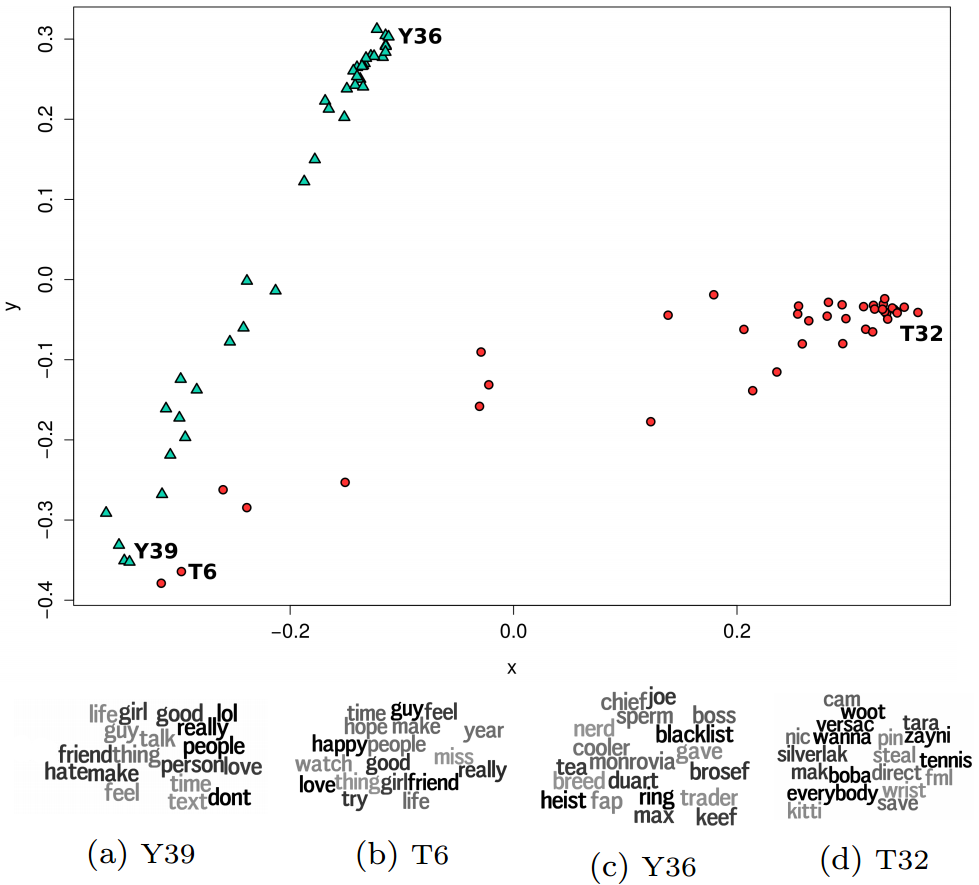
The green triangle markers represent topics extracted from Yik Yak while the red circles represent those extracted from Twitter (40 topics each). The dominant words that contribute to a sample of four topics are shown below the MDS graph. Topics Y39 and T6 are shown to be the most similar (as they are clustered together in MDS space) while Y36 and T32 are quite far apart indicating a significant dissimilarity in topics. Overall, what this figure ends up showing is that on average the topics discussed on the Yik Yak platform are notably different than those discussed on Twitter. This is just one of the similarity methods used in this research and I encourage you to read the full paper if you are interested in additional details.
Well, that is it for this blog post. I just wanted to post a small taste of the research and development work that we’ve been doing on the data science team here at SpatialDev. Look for many more posts related to data science in the months to come as we are continuing to explore new and exciting options to better answer some of the world’s most complex geospatial problems.