



Introduction
The Value Proposition of Open Data
Data is the fuel of the current information age revolution. Numerous sources have pointed out that more data is generated today than at any other time in history. Today’s data is richer, more heterogeneous, and increasingly more complex than the data of years past. This is especially true of spatial data. Advances in computing and networking capabilities, as well as the evolution toward organizational transparency, offer the opportunity to leverage this rich landscape of data to drive massive social, political, and economic change. With open data – those data which are provided openly for others to use freely – becoming more commonplace, and the tools to consume, analyze, and publish huge amounts of data becoming more accessible, just about anyone has the ability to use spatial data, enhance it, and make it locally relevant to them on a map.
The Open Data Movement
The initial power of open data lies in its availability and accessibility. But much more than that, its value lies in the ways varied datasets can be combined, analyzed, and visualized to inform, communicate, and enhance understanding of the world around us.
Built on robust foundational architecture and interoperability standards, open data practices have evolved significantly in the past few decades. Not only have governments and NGOs responded to the call of open data access, but also partners in industry are increasingly encouraging their clients to amend copyright permissions and publishing access to what once was proprietary data.
As permissions and access to these datasets have changed, new tools and frameworks have emerged. This has enabled public participants and commercial data producers to openly publish their data though online sources. One key institutional innovator in this movement (among many) has been the World Bank. The World Bank has completely changed course and now publishes global indicator data (http://data.worldbank.org/). Other large federal and private organizations have followed suit. Today, there are examples of open data platforms, tools, and policies everywhere – from local jurisdictions to federal governments and countries in sub-Saharan Africa.
 Example of far reach of open data: HTTPS://WWW.OPENDATA.GO.KE/
Example of far reach of open data: HTTPS://WWW.OPENDATA.GO.KE/
In academic circles, the case for opening data is convincing. There have been numerous other discussions on the value of openly publishing data with limited restriction (Gardels & Buehler 1994, Auer & Zipf 2009). A plethora of scientific studies and real-world use-cases agree that open data works for extending our understanding and serving the greater good. (Gardels 1994, Auer 2007, Bizer et al. 2009, Chua 2009).
The Intersection of Geospatial
Beyond the academic arguments in the value for opening data, we can clearly see a ripple effect, with more organizations publishing their data and more private and public sector companies working to facilitate that process. In addition to the abundance of rows and columns being published online daily, access to geospatial data is increasing. This trend is of particular interest to the growing geospatial community.
While many organizations already leverage the wealth of content stored in their private data silos, an increasing number have started to take advantage of the abundance of freely available, open geospatial data accessible today. More and more organizations have elected to open access to their data silos realizing that the big picture can only be seen through linking spatial datasets from a wide range of providers. For example, by linking geospatial data with open data related to population centers, banking facilities, and roadway networks, an NGO can prioritize investments in financial access and micro-credit for underserved areas. Most of the global-scale questions that are being asked today can only be understood through a comprehensive and global understanding of the problem at hand.
Many organizations have started to leverage the wealth of information stored in their geospatial libraries. This extends to the larger mezzo scale thematic problems such as mitigating climate change to more pedantic, local scale of where to find parking.
 City of Seattle’s parking app links geospatial and open data
City of Seattle’s parking app links geospatial and open data
Many other organizations don’t yet know how to leverage their data. The complex task of publishing data is being simplified with the continued and expanding investment and new Open Source platforms – such as CKAN (by the Open Knowledge Foundation), GeoNode, and GeoNetwork, as well as proprietary vendors such as Socrata and Esri. However now that so much data is public, the challenge has shifted from accessing the information to digesting what’s out there and making sense of it. Because geospatial is often added as a core data type to most catalogs, non-experts are being forced to work within the unfamiliar fundamentals of geography. Visualization of geo-enabled big data is a quickly growing and evolving market. Therefore, the main challenge ahead is how best to analyze and visualize the information spatially.
Why Spatial?
## Examples of Open Geospatial Data and Information The publication and use of geospatial data is widespread. Spatial information has been mainstreamed into portals and catalogs that were not originally designed to support it. For example DKAN and CKAN both support limited geospatial search, discovery, and download. Data.Gov, arguably one of the biggest portals for open data in the United States, supports geospatial information as a core feature. Thousands of datasets are available for direct download and immediate use.
The OpenStreetMap Use Case
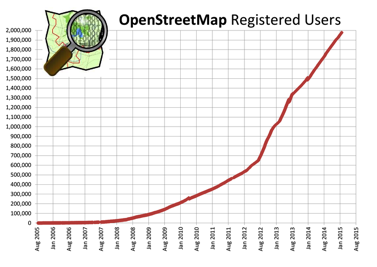
One of the most prominent examples of openly available and crowdsourced geospatial data today is OpenStreetMap (OSM). OSM is a collaborative project to create a free, editable map of the world. OSM strives to overcome the barriers associated with private licensing of map data and the advent of inexpensive portable satellite navigation devices. Users can collect data using manual survey, GPS devices, aerial photography, in-browser editing, and other free sources. This crowdsourced data is then made available under the Open Database License. OSM is open data, meaning anyone can copy, distribute, transmit, and adapt it, as long as they credit OSM and its contributors. The site is supported by the OpenStreetMap Foundation, a non-profit organization registered in England.
Presenting the Spatial “Data Story”
Tables and charts only provide a two-dimensional data story. A geospatial dimension can uncover additional insight by providing a view that can be contextualized on a local map. In the case of the farms in Kenya, the geospatial dimension would show the distribution and growth or shrinkage of agricultural areas over time. For an organization providing funding for education and infrastructure programs in an urban areas, it would be clear where investments are currently located, as well as where critical gaps exist.
The power of open data and geospatial data is further compounded when sites allow individual users to share with the world their own view of the data. When this door is opened, others can view, extend, and remix that story into something completely different and unique. Visualizing stories on localized maps helps people draw inferences that are not, and will never be, possible on a chart or graph. The presence and availability of spatial data makes this all possible.
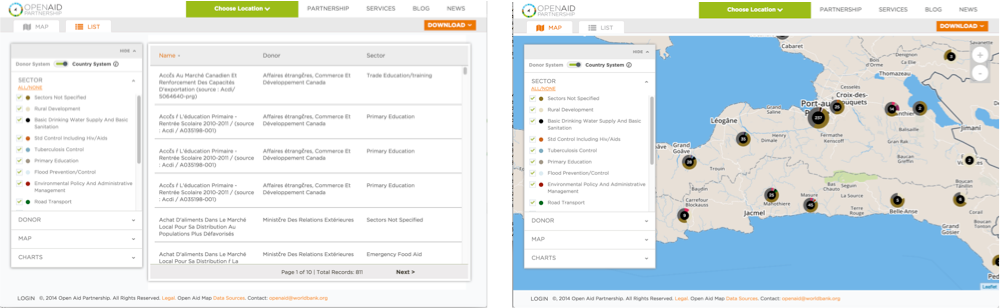 Geospatial context enriches meaning of tabular data
Geospatial context enriches meaning of tabular data
Top Trends in Open Data
As the open data movement grows in size, so too has the development of toolkits, frameworks, and Application Programming Interfaces (APIs) for handling the large amounts of data. A number of high profile and early adopting commercial organizations – such as Tableau, Dataverse, and CartoDB – have jumped on board, offering a range of tools for exploring, analyzing, integrating, and visualizing the copious amount of open geodata available today. With the dramatic rise in user-generated geo-content coming from mobile-enabled platforms (e.g., online social networking, location-based services), the need for big data analytics and scientometric applications is clear.
In the geospatial realm, companies such as Socrata and ESRI, and organizations such as the OGC and W3C, have been leading the charge in setting open data standards and building extensible analytical tools for searching, organizing, and understanding the massive amount of data accessible. Many of the groups are paving the way to cutting-edge open data technologies such as linked spatial data and geo-semantics (Berners-Lee et al. 2001, Janowicz et al. 2012). Now that much of the underlying plumbing that enables the open data movement is firmly place, we’re going to see the continuation and acceleration of a number of key trends.
Occasionally people refer to ‘big data’ when talking about open data. The idea of big data is generally comprised of four pillars; Volume, Variety, Velocity, Veracity. The vast majority of open data sites and catalogs present the “Variety” challenge as the data – particularly the spatial data –is wildly disparate. Over the next several years we should expect to see organizations rethinking Open Data to address the variety problem. This could include increased development on the interoperability of metadata or furthering global initiatives that attempt to harmonize information through the development of ontologies.
1. Moving Up the Open Data Value Chain
The challenge now has become how to better digest and make sense out of the glut of data that is published online. This is not a simple feat, as the data is largely heterogeneous across (and within) organizations and does not lend itself to creating simple charts or maps from tables full of poorly behaved data. In the coming months and years, we’re going to see a greater effort levied upon creating workflows that allow the combination of disparate data that ultimately will create clean datasets, relative to what we see today.
Developing analytical tools that can mine that information to tell a story or generate additional insight is far simplified once the data are clean. In this sense, an emphasis on the ability to produce on-line analytics that unveil the true value of information will outstrip the importance of simply publishing one’s data.
2. Increasing the Open Data Ecosystem of Data and Tools (geo)
As the evolution of openness and transparency has expanded over the past several years, the global ecosystem of open data has exploded. The open data policies that have been implemented in recent years will continue to gain momentum and be realized with actual data. Likewise, the specialized skills and training traditionally required to leverage the value in geospatial information will continue to evaporate. This will ultimately result in a robust ecosystem of data publishers alongside a rich set of hosted tools that allow average people to gain insight and intelligence from the published data.
3. Global Expansion of Open Data (Kenya example)
The drive towards expanding transparency is not just a phenomenon in the United States and Europe. We are seeing the global expansion of open data publishing. There are specific examples in Nepal and Kenya plus expanding global initiatives such as GODAN and IATI. “Open Data Days” are now a global phenomenon as are hackathons, appathons, and the like.
This trend will continue to accelerate. The drive towards transparency – as well as the tools to enable it – will continue to outpace existing governance structures to manage it. And as developing countries see new means to diversify national economies, demand for the geospatial information to help drive those decisions will continue to rise.
4. Extension of Citizen Engagement Tools (more data and analytics)
Increased citizen engagement – both in the consumption and creating of data – will continue to expand. Increased transparency, better tools, and more informative analysis will open up government data to constituents in entirely new ways. Meanwhile, the growth of mobile applications that facilitate communication with both local and national governments will continue to drive citizen engagement. For example, in Seattle apps like FindItFixIt allow and encourage citizen reporting. Global initiatives like OpenStreetMap encourage citizens to map their neighborhood, thereby closing the loop with government entities. Finally, programs such a Missing Maps encourage groups of users to data information to areas where there is none thus literally filling in the missing map. The continued development of the OpenMapKit will introduce yet another method for data collection in the hardest to reach area.
 OpenMapKit is a mobile data collection tool in development
OpenMapKit is a mobile data collection tool in development
Conclusions
Organizations are being pushed into the Open Data ecosystem while the tools that facilitate publication are rapidly reaching maturity. The online deluge of data that is already here will continue to evolve and expand to new levels of complexity. That expansion will include increasing amounts of spatial information from a multitude of sources from Landsat images from NASA to community level data from OpenStreetMap. The tools to analyze and visualize that spatial data will need to evolve just as quickly in order for anyone to uncover patterns and discover actual information from all the noise.
References
Auer, M., and A. Zipf. “How do Free and Open Geodata and Open Standards fit together? From Skepticism versus high Potential to real Applications.” The First Open Source GIS UK Conference. University of Nottingham. UK. 2009.
Gardels, K., and K. Buehler. “Open GeoData Interoperability Services: An object-oriented framework for accessing distributed, heterogeneous geographic information.” Proceedings of the 6th International Symposium on Spatial Data Handling. 1994.
Bernard, Lars, et al. “Scientific geodata infrastructures: challenges, approaches and directions.” International Journal of Digital Earth 7.7 (2014): 613-633.
Chua, June. City of Vancouver embraces open data, standards and source. CBC News. http://www.cbc.ca/news/technology/city-of-vancouver-embraces-open-data-standards-and-source-1.838987, 2009. Retrieved February 8, 2015
Janowicz, K., Scheider, S., Pehle, T., and Hart, G. (2012). Geospatial semantics and linked spatiotemporal data–Past, present, and future. Semantic Web, 3(4), 321-332.
Berners-Lee, T., Hendler, J., & Lassila, O. (2001). The Semantic Web. Scientific American, 284(5), 28-37.
Auer, Sören, et al. Dbpedia: A nucleus for a web of open data. Springer Berlin Heidelberg, 2007.
Bizer, Christian, Tom Heath, and Tim Berners-Lee. “Linked data-the story so far.” (2009).
WEB
http://data.gov.uk/sites/default/files/Open_data_White_Paper.pdf
http://data.worldbank.org/about/open-government-data-toolkit/knowledge-repository
http://en.wikipedia.org/wiki/OpenStreetMap
http://www.wired.com/2013/08/power-of-amateur-cartographers/