



Data APIs, like all code, should be tested. Unit testing works well for certain API components, but often times you want to test an API service endpoint itself. You may want to answer these questions:
1) Does the endpoint still exist? URLs can get changed, files can mistakenly get removed, etc. Having an API endpoint under test can alert you to such issues.
2) Does the endpoint return the data structure you expect? Changes in the API or in the database/persistence-layer can lead to property/column name changes or even data-type changes.
3) Does the API endpoint handle errors properly?
4) Do API endpoints that execute downstream CREATEs, UPDATEs, and DELETEs in your database/persistence layer actually fulfill their objective? Does the persistence layer change state as you intended?
Below, I will illustrate a testing pattern that I use to answer the above questions prior to every API deployment.
What are we testing?
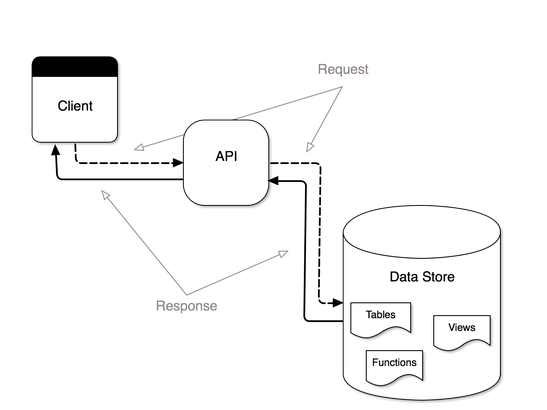
The diagram above illustrates a pretty typical setup – a client (native/web app) requests data from an API service, which in turn requests data from a datastore, and a response flows back through the chain. In short, what we are trying to test here is that the client receives the response it is expecting, and that a “successful” response is not a false-positive. To be clear, these are not “unit-tests”, in that we are not atomizing our code and testing each individual piece. Instead we are testing the API service endpoints as black boxes (see the image at the top of this post). If a test fails, we at least know that particular blackbox is broken and we can investigate the source of the problem. The next diagram details potential sources of failure in our data-service blackbox, and thus what problems our integration tests may bring to light.
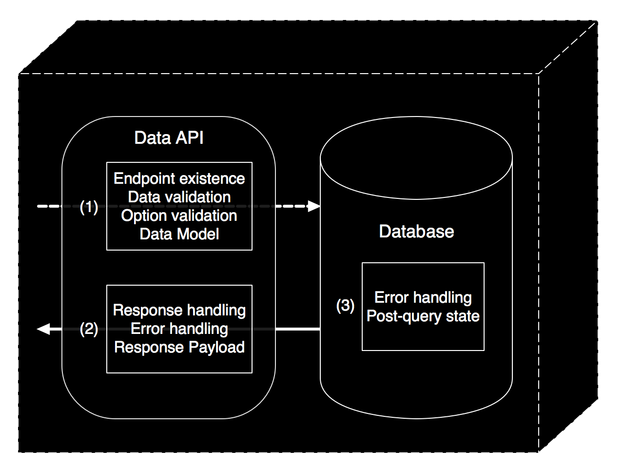
Complications to consider before testing a data API
Complication #1: Need a known, initial-state for the database
We need a real database to perform the integration tests and it has to be in a “known, initial-state” before every test-suite execution. I considered using mocks instead of real data, but we want to actually include testing the database-layer as part of our integration tests (did the schema change since our last test, do functions work as intended, are permission correct?). Mocks would circumvent all that and we would have to setup a different system to test the database. (Note that in my current role, I am the developer for both the API and the data-store, so it makes sense to integrate the tests. In other situations, it might not.)
We need the database to be in an initial “known-state” before every test-execution because the API service requests often rely on specific record IDs being present, and the attributes for those records need to be in a certain state to confirm the responses with assertions. Think about these examples:
Example 1: We want to test whether an endpoint that performs a CRUD update does so successfully. We need to be sure the id of the record we want to update is exists, and we also need to know the attribute to update is in its initial state, so that a follow-up assertion can confirm the old value was replace by the new value during the test.
Example 2: We want to test whether an API service performs a CRUD delete successfully. We need to be sure the record that we want to delete is present at the outset of the test, we need to know its ID it order to perform the delete as well as to assert that the record is no longer there after the delete is complete.
Complication #2: APIs often require authenticated requests
Integration testing means hitting the service endpoint as if it were a real API, and real APIs often require authentication. Authentication is part of the APIs functionality, so it makes sense to include it as part of the test to ensure its functionality (as opposed to “switching it off” during the test execution). So, where required, test-generated API requests must provide a means of authentication. Without it, the test request will be denied.
We leverage JWT as part of our authentication pattern, and it makes working around this complication relatively easy. We simply obtain a valid JWT as part of the test-suite setup and attach that as the authentication header of each test-request. How you obtain the JWT depends upon how it is used in the request – some JWTs may contain information used in the request (beyond the simple pass/fail of the valid JWT itself). In a future post, I will detail the method we use for this type of test request authentication.
Complication #3: Test the database state, not just API response-payload
Non-read API service endpoints usually result in a change to the state of the database. The response from such endpoints may not explicitly confirm the state change. For example, an endpoint that deletes a table record, may simply send back a message stating the delete was successful – but was it? Asserting on an API response in this case may not provide the confidence we’d like.
Our workaround in this case is to perform a followup query on the datastore that can confirm the database state has changed how we expect (e.g., there is no longer a record in the database with the ID of the record we just deleted.)
The data API integration testing environment
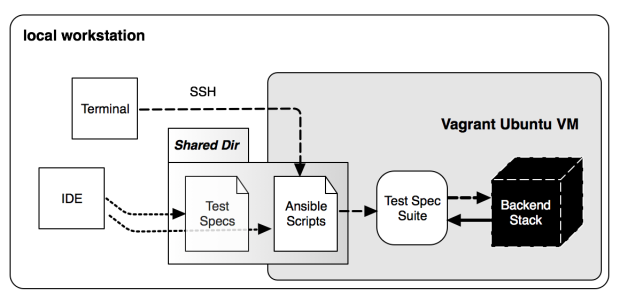
If you read my previous post on using Vagrant as a development environment, the figure above may be familiar. This architecture isn’t critical for integration testing, but we have found it makes things easier. We have a Vagrant Ubuntu virtual machine (VM) that has our backend stack installed on it. This is essential because we can provision the VM so that our tests use the same software and OS as our production deployment . A shared directory connects the local workstation and VM so that we can use our workstation’s IDE for editing code. We use Ansible playbooks (via SSH) to execute test-setup steps and then fire off the test suite, as Ansible provides a nice toolset for doing the test-setup tasks that require interfacing with various softwares.
Integration Testing Sequence
Step 1: Create a “Test Suite” database
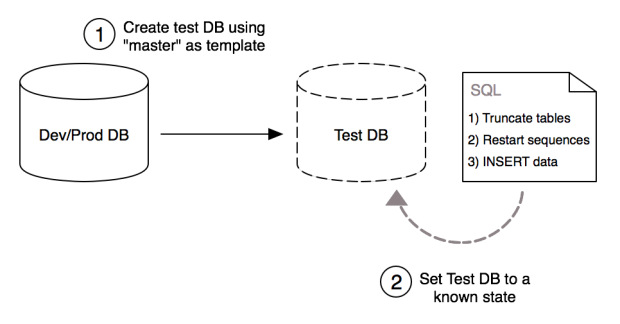
This part of the test-suite sequence addresses complication #1, getting a data-store into a known, dependable state. Since we don’t want to alter our development or production database, we make a copy of it. Then we truncate tables that need to be filled with known data, restart the primary key sequences on those tables, and finally insert the known data on those tables. At a minimum you’ll need to do this after any schema changes. Choosing to copy before the execution of each test suite may save you some work truncating and inserting data (e.g. data for read-only API services) but the practicality of this depends upon the size of the database. For medium to small sized Postgres databases, creating a new database by using another database as a template is very quick. (As an aside, I’ve scripted the database copy and SQL truncate/insert as part of an Ansible playbook, though it could be easily accomplished with a shell script).
Note: there are alternatives to copy DB/truncate/insert data approach. You could potentially try to get your datastore into a known state with “before” functions (see Mocha.js) prior to each test, and then revert with “after.” It’s also possible to use transactions to prevent the persistence of any tests that involve INSERTs, UPDATES, or DELETEs. But these approaches felt more complicated and not substantially more transparent.
Step 2: Get and use an authorization token
As noted above (complication #2), many data APIs require authenticated requests. So the testing regime will either have to disable the authentication requirement or provide the required authentication mechanism with the test request. Since we use JWT, it is as simple as generating a valid token before your test suite and distributing that token to each test that sends a request to an authenticated API. We’ll have a post on our method of doing this with Mocha and Node.js in the future.
Step 3a: Execute the test suite and assertions on response
We use Mocha and Supertest to fire off numerous requests to each API service endpoint. We test each response for a 200 code (success). If there was a problem, error codes hint at the source (404 – bad URL, 400 – bad input data, 500 – database error). If test receives a 200 code, than we can assert on the response payload. Since our database is in known state, we can know in detail what our response payload should be and thus develop fine-grained assertions. In addition, we can test our error handling; if we write our test to intentionally send faulty input data, we can ensure that our API handles it gracefully and that proper code and messaging is delivered.
Step 3b: Execute follow-up requests/queries to confirm database state
Not all API interactions with a database provide proof that what you think happened actually did happen (complication #3). You can assert on the API “success” response, but since these integration tests are meant as a catch all for the API/DB ecosystem, a followup query to the database can provide a definitive test result. So, for example, after firing off a test on an API endpoint the deletes a user, you can do second (perhaps direct) request to the database to see if that user is really no longer a record in the user table.
Scripting the whole test procedure
I use Ansible for most of my IT automation tasks, and so I have applied it to setup and execute our API/DB integration test suite. Here’s a sample Ansible playbook that roughly outlines the procedure discussed above. If you’re not an Ansible user, you could easily convert this to a shell script.
Final thoughts
This integration testing pattern provides broad test coverage for the data API and its associated database layer. While not as granular as unit testing, it can alert the developer to a problem at some point in the request/response chain. If you have careful managed and messaged errors in your API and database, test output is usually good enough to allow a rapid diagnosis of error sources, whether the breakage is in API code or in the database schema, functions, or permission. In our own projects, this testing pattern has been crucial for developing, maintaining, and extending our code.
The details of this pattern are particular to the technical stack, authentication pattern and development environment, so just the broad outline was presented for now. I’ll have more posts soon regarding the details of each of the steps above using Ansible, Node.js, Mocha, Express.js and Postgres.